
¿Alguna vez se ha preguntado realmente qué es Big Data y cómo afecta los negocios? ¿Dónde comenzó está revolución tecnológica y qué estándares sigue para cumplir con sus objetivos? Conozca la respuesta a estos y otros interrogantes en este artículo porque vivimos en un mundo inundado por los datos.
“Big data es como el sexo en la adolescencia: todo el mundo habla de ello, nadie sabe realmente cómo hacerlo, todo el mundo piensa que los demás lo están haciendo, así que todos afirman que lo hacen”: Dan Ariely, escritor y profesor de la Universidad de Duke.
Este comentario humorístico sobre Big Data revela una tendencia, un comportamiento que muchas veces se repite en el mercado tecnológico, que es el uso de términos de moda sin entenderlos realmente. Esto sucede con la Transformación Digital, la virtualización, las redes definidas por software, el aprendizaje automático y, por supuesto, con Big Data.
Vivimos en un planeta que recientemente experimentó una Transformación Digital acelerada por la pandemia, donde la población se volcó más que nunca a los canales digitales. Así, en 2023, diariamente, los usuarios de WhatsApp intercambian 6.500 millones de mensajes y s envían más de 333.200 millones de correos electrónicos.
Pero estas cifras inmensas no son Big Data. Esta tendencia no se refiere solo a la inmensa cantidad de datos que se generan en el planeta; su alcance va más allá de eso. Big Data trata de cómo se utiliza la información.
Para entenderlo, podemos tomar la famosa frase del matemático y científico de datos británico Clive Humby, quien en 2006 dijo: “Los datos son el nuevo petróleo”. Una expresión que fue precisada posteriormente por el analista Michael Palmer, quien usando la misma analogía aclaró que “los datos son valiosos, pero si no están refinados, en realidad no se pueden utilizar. El petróleo debe transformarse en gas, plástico, productos químicos, etc.”.
Vivimos en un mundo de datos no desprovisto de desafíos, con regulaciones diferentes según la geografía, provenientes de millones de dispositivos que se han visto empoderados por las nuevas redes móviles (5G), que prometen revolucionar el Internet de las Cosas y generar más datos que nunca.
Esta demanda de soluciones tecnológicas para el análisis y manipulación de información han estimulado el surgimiento de una generación de proveedores tecnológicos que conforman un mercado gigantesco de 162.000 millones de dólares en 2021, y se estima que superará los 273.400 millones en 2026.
En otras palabras, hablamos de una revolución en marcha y por ello es más importante que nunca precisar los conceptos. Así que comencemos con lo básico: ¿qué es Big Data?
Índice de temas
¿Qué es Big Data?
Para la firma analista Gartner, Big Data trata de activos de información de gran volumen, velocidad y variedad, que exigen formas rentables e innovadoras de procesamiento para mejorar la comprensión, la toma de decisiones y la automatización de procesos.
O si queremos una versión más sencilla, podemos decir que Big Data es un término que describe el gran volumen de datos –estructurados, semiestructurados y no estructurados– que inundan una empresa todos los días.
Pero lo realmente importante, no es la cantidad de datos que se captan, sino cómo se usan. Big Data no busca acumular datos ni procesarlos; el fin último es generar insights, información relevante que ayude a la mejor toma de decisiones.
¿De dónde salió?
Aunque el origen del término Big Data surgió a mediados de la década de los noventa, se le atribuye su popularización al investigador estadounidense John Mashey por su texto: “Big Data and the Next Wave of InfraStress Problems, Solutions, Opportunities”.
¿Y por qué surgió en esa época? Porque la información los estaba inundando.
En los años 90 nació Internet, abriendo la puerta a la siguiente avalancha de información que llegaría con la Web 2.0, en la cual el contenido en línea ya no solo sería creado por las grandes empresas, y en su lugar, la mayor parte del mismo sería generado por los usuarios desde las redes sociales.

Gráfico: Statista.
Esta tendencia se vio reforzada por el surgimiento de los smartphones y las mejoras en las redes móviles, que cada año serían capaces de transmitir más y más datos. Así, se pasaría de generar globalmente 2 zettabytes de información en 2010 a más de 120 zettabytes para 2023.
O tal vez, el ejemplo más dramático ocurrió en 2018 cuando los medios reportaron que 90 % de todos los datos generados por la humanidad, hasta ese día, se desarrollaron en los últimos 2 años.
Esta cantidad de información representó una espada de dos filos para las empresas. Por una parte, nunca habían tenido acceso a tantos datos y no estaban seguros de su capacidad para procesarlos. Pero al mismo tiempo, en esos datos estaba la clave para tomar buenas decisiones y definir el perfil de las organizaciones modernas: las empresas data-driven.
Las 3 y las 5 V de Big Data
Aunque originalmente, en 2001, el analista de Gartner Doug Laney determinó 3 grandes V que definen al Big Data, que son Variedad, Volumen y Velocidad, esta definición se ha ido ampliando con los años, y ahora se habla de las 5 V, que incluyen Veracidad y Valor.
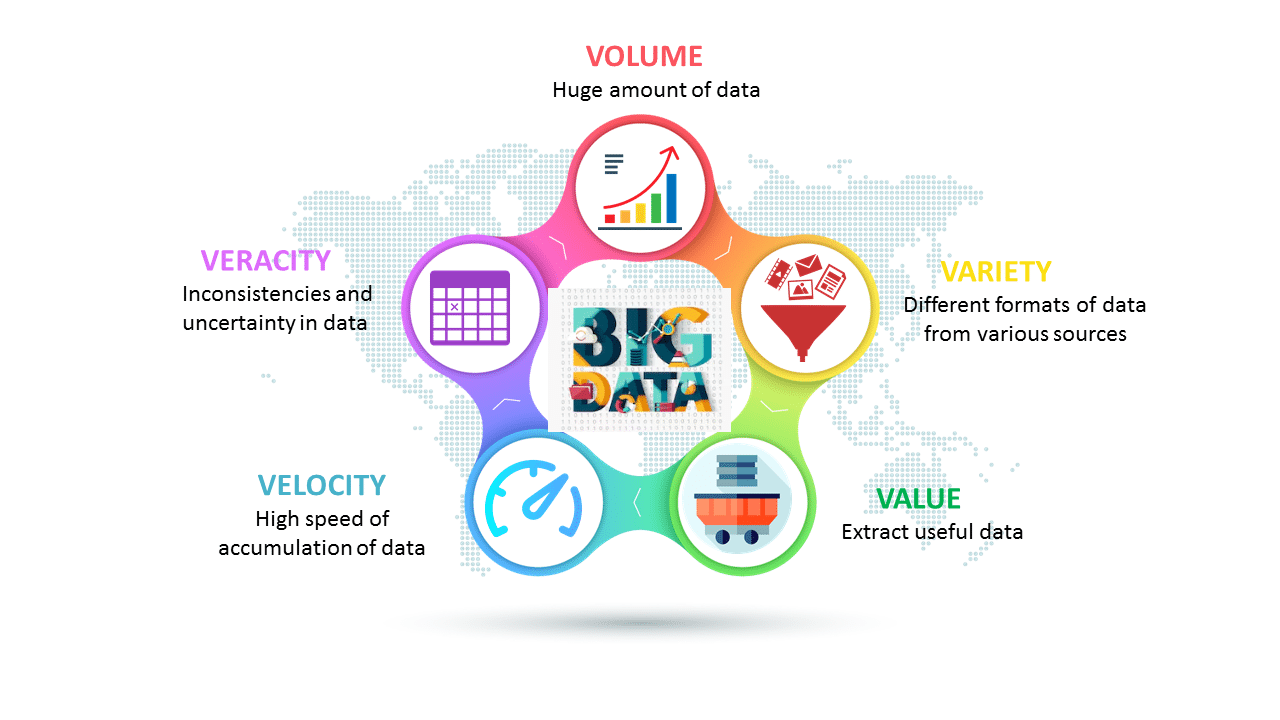
Gráfico: Edureka.
De esta forma, para que unos datos sean considerados Big Data, se requiere que tengan:
Volumen: Es tal vez la característica más esperada de Big Data, y es el tamaño cada vez más grande de los datos que entran en cualquier organización. Una variable que crece gracias al potencial de las nuevas redes móviles y de la nueva generación de dispositivos que la conforma (Smartphones, cámaras de seguridad, IoT, etc.).
Variedad: No todos los datos son iguales. El vídeo, las fotos, la ubicación geoespacial, la cantidad de compras de una empresa, todos ellos suelen tener sus propios formatos: jpg, .xls, mp4, etc. Los datos suelen variar según el nicho de mercado y por ello, Big Data suele estar compuesto por innumerables fuentes de información.
Velocidad: Los datos deben estar presentes cuando se les necesita. En algún momento, las cartas y los telegramas fueron los medios de comunicación más rápidos de su tiempo, pero esto cambió con la tecnología. Ahora los datos se necesitan en tiempo real: piense en una emergencia, un desastre natural, la caída en el precio de las acciones, etc. No solo se deben capturar rápido, también procesar con la misma urgencia.
Veracidad: Añadida posteriormente, la veracidad incluye una variable fundamental y es la calidad de los datos: ¿qué tan útil es un dato si es inexacto?, ¿su fuente es de confianza?, ¿se presentan anomalías?, ¿inconsistencias?, ¿es un dato duplicado? La respuesta a estos interrogantes determina el valor real que pueda tener la información.
Valor: La última variable para muchos es la más importante y es el valor que se pueda generar con base en los datos. Todas las empresas pueden llegar a tener la misma información y herramientas tecnológicas para trabajarla, pero el valor, el impacto en el negocio que cada una pueda sacar de ellas, eso es diferente.
Fuentes de Big Data, tipos de datos
Para entender cómo funciona Big Data, debemos entender que no todos los datos son iguales, así como tampoco lo son su procedencia. Por ello, en Big Data hablamos de datos estructurados, datos semiestructurados y datos no estructurados.
Los datos estructurados son aquellos que ya han sido organizados en un repositorio. Suelen clasificarse como datos cuantitativos y son los típicos que vemos en hojas de cálculo, formularios web, encuestas digitales, hojas de Excel con direcciones, formularios, etc.
Precisamente por su orden, los datos estructurados son los más fáciles de usar y se gestionan usando el lenguaje de programación Structured Query Language (SQL) y bases de datos relacionales.
Entre 80 % y 90 % de los datos existentes en el planeta son datos no estructurados. Su abundancia se explica cuando consideramos su naturaleza, porque pueden ser cualquier cosa, desde una imagen en una red social, hasta mensajes de audio, información de un sensor IoT en un cultivo, un vídeo en una red social, etc.
La data no estructurada suele ser más cualitativa y, por su variedad, puede almacenarse dentro de una base de datos no relacional o NoSQL.
Por su parte, los datos semiestructurados están en la mitad, usando elementos de ambos mundos. Una foto, por ejemplo, es información no estructurada, pero si es tomada desde un teléfono, puede estar relacionada directamente con valores numéricos como fecha y direcciones.
¿Cómo funciona Big Data?
Ahora que conocimos los diferentes tipos de datos, la materia prima de Big Data, podemos saber qué pasa con ellos. Se trata de varios pasos que van desde la captura de la información hasta la toma de decisiones. Un proceso que, en más detalle, se divide en:
Recolección de los datos: según los objetivos establecidos, se comienza a buscar información relevante que pueda aportar a esta meta. Esta información puede venir de diferentes fuentes y ser de diferentes tipos.
Preprocesamiento de los datos: no todos los datos son útiles, por lo que se comienza con un primer filtrado de la información para asegurarnos de su calidad. Es en esta etapa cuando hablamos de integración, limpieza, reducción y transformación de los datos.
Almacenamiento de los datos: todos estos datos seleccionados deben separarse del resto y guardarse en diferentes bases de datos, nodos y dispositivos para ser tratados, ya sea desde servicios en la nube o en equipós in-house.
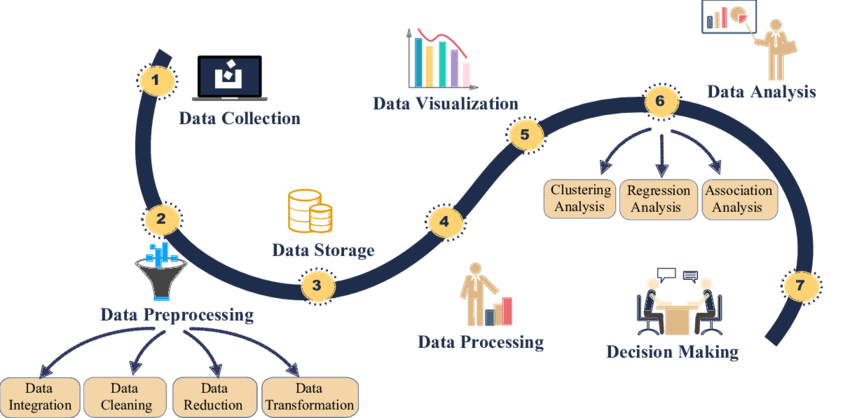
Gráfico: Researchgate.
Procesamiento de los datos: en este paso, debemos aplicar diferentes programas de minería de datos para detectar patrones y anomalías dentro de la información.
Visualización de los datos: no importa qué tan buenos sean los programas de análisis de datos si la interfaz de usuario es deficiente o confusa. En esta parte, la información es presentada ante los expertos.
Análisis de datos: en esta fase se establece el tipo de procesos al cual someteremos la información, ya sea agrupamiento por similitud (clustering), por relaciones entre datos (asociación), por relación entre variables (regresión), etc.
Toma de decisiones: es el punto final por el cual se emprendió todo el camino, y es tener la información necesaria para tomar una buena decisión basada en datos.
Desventajas y ventajas de Big Data?
Nadie considera de por sí que tener información a la mano sea algo negativo; sin embargo, el problema con Big Data es la magnitud y diversidad de la materia prima, una situación que puede ser desafiante para algunas organizaciones si no cuentan con los recursos para sacar ventaja de los datos. Pero los precios están bajando y las ventajas del Big Data son demasiado importantes para ser ignoradas.
Algunas de estas ventajas son:
Incidencia en la mejor toma de decisiones: Big Data permite que no se tomen decisiones a ciegas, informando a las empresas sobre sus finanzas y ventas, el estado del mercado (la competencia), los retos, e incluso permite detectar patrones de comportamiento y nuevas tendencias antes de que estas se conviertan en los nuevos estándares.
Big Data proporciona el combustible para que los algoritmos encuentren nuevos patrones y puedan generar modelos predictivos.
Optimización de los procesos: Una de las partes más importantes de Big Data es saber cómo está funcionando, por dentro, una organización. Una visión que permite ayudar a mejorar los procesos y, por ello, reducir costos. De hecho, 59,4 % de los encuestados de diferentes empresas ha afirmado que usa Big Data precisamente para eso.
Ayuda a prevenir el fraude: Usada especialmente en los servicios financieros, Big Data proporciona la información necesaria no solo para detectar transacciones ilegales (robo de tarjetas, suplantación de identidad, etcétera) y detectar anomalías, sino que también permite calificar el historial crediticio y de riesgo de cada cliente.
Desarrollar un marketing más acertado y personalizado: Big Data permite conocer mejor a los clientes. Catalogado por analistas como un imperativo estratégico, esta tendencia muestra el camino para lograr establecer una conexión emotiva con los usuarios al entregar productos a la medida, cuando y donde los necesiten. O dicho de otra forma, Big Data facilita la vida de los clientes, mejorando su experiencia de uso (UX).
Permite establecer mejores alianzas: En medio de un mercado tan competido, es vital saber qué socio de negocios puede proporcionar una ventaja sobre la competencia. Big Data puede entregar esa respuesta al proporcionar información sobre qué le conviene más a cada organización, qué necesita y quién puede proporcionarlo.
Pero estas características son un lado de la moneda, porque Big Data también presenta retos como los siguientes:
La falta de talento: Es un fenómeno global que enfrentan todas las empresas tecnológicas. Para ser más exactos, se estima que para 2030 habrá una escasez mundial de más de 85 millones de trabajadores en ciencia y tecnología, lo que representará una pérdida de ingresos anuales de 8,5 billones de dólares. Los científicos de datos y analistas se encuentran en este listado.
Riesgos de seguridad: Los datos son uno de los activos más buscados por los delincuentes modernos, como lo demuestra el secuestro de información o ransomware. Tanto es así que esta modalidad delictiva generó más de 493 millones de ataques en 2022 y evolucionó hasta convertirse en un servicio conocido como Ransomware-as-a-Service (RaaS).
Regulación: Vivimos en un mundo conectado con innumerables operaciones transnacionales, pero los datos no son tratados de la misma forma en todas las naciones. La Comunidad Europea tiene diferentes exigencias referentes a la privacidad y al manejo de los datos de sus ciudadanos, comparados con las regulaciones asiáticas o latinoamericanas y esto es solo un ejemplo.
Costos: Aunque las tecnologías se han ido democratizando, también es cierto que la inmensa cantidad de datos que se generan diariamente impone la necesidad de usar nuevas herramientas de analítica. Esto quiere decir que hay costos que no todas las organizaciones están dispuestas a invertir.
Garantizar la calidad de los datos: No todos los datos son relevantes, incluso aunque no estén duplicados y no presenten distorsiones. La información adecuada para un proceso solo puede ser garantizada si es completa, adecuada y precisa. Para este fin, existen estándares que buscan garantizar estos procesos.
¿Cuáles son los estándares de calidad de datos?
A primera vista, se puede decir que la calidad de los datos es la cualidad de los mismos para ser usados en una organización, cumpliendo con características como exactitud, integridad, exhaustividad, coherencia, validez, unicidad, actualidad y que sean completos, entre otras variables.
Pero también es cierto que no todas las partes de una organización comparten las mismas exigencias. Es decir, para las áreas de negocio, la calidad de los datos se define en función de su relevancia, facilidad de acceso y puntualidad, mientras que para las áreas de sistemas está más relacionada con su participación en los procesos informáticos.
A pesar de esas diferencias, existen estándares independientes para definir esta calidad, como son las normas ISO (International Organization for Standardization) 8000 y las ISO 25000.
La ISO 8000 tiene como fin garantizar la calidad de los datos que se intercambian entre dos organizaciones. Aprobada en 2009, esta norma está compuesta por cuatro grandes ejes relacionados con la naturaleza de la calidad de los datos, su gestión y evaluación, el intercambio de los “datos maestros” y la información de ingeniería.
La ISO 25000, aunque enfocada en evaluar la calidad en la producción software, tiene una subdivisión, la ISO 25012, que define un modelo de calidad de datos para datos almacenados en un sistema informático. Dentro de este marco, se establecen una serie de requisitos para estos datos que se dividen en inherentes y dependientes.
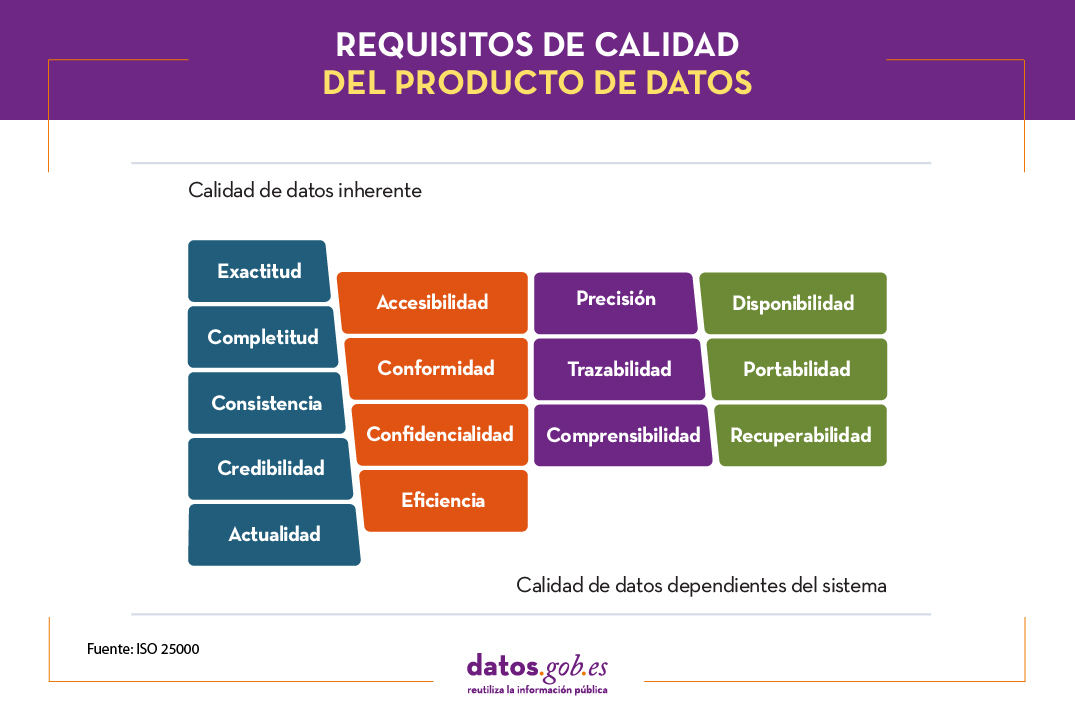
Gráfico: Datos.gob.es.
La calidad de datos inherentes son propias del mismo dato, independientemente de su contexto o uso, como lo son su exactitud, consistencia, completitud, credibilidad y actualidad. La calidad de datos dependientes viene definida por su uso, con ejemplos como la disponibilidad, recuperabilidad y portabilidad.
También existen otras variables intermedias entre estas dos grandes divisiones que incluyen cualidades como conformidad, accesibilidad, confidencialidad, eficiencia, precisión, comprensibilidad y precisión.
Tecnología y Big Data
Es complicado imaginar las tendencias tecnológicas de forma independiente, ya que estas siempre trabajan en conjunto. Por ejemplo, Big Data y la analítica, la computación en la nube y el almacenamiento, la analítica predictiva y la inteligencia artificial, por dar solo algunos ejemplos. Sin embargo, si simplificamos un poco podemos dividir Big Data en cuatro grandes componentes tecnológicos como son:
- Almacenamiento de datos.
- Minería de datos.
- Analítica.
- Visualización de datos.
Como su nombre lo indica, las tecnologías de almacenamiento de datos se relacionan con la capacidad de buscar, gestionar y almacenar información. Algunas de las herramientas más usadas en este campo son Apache Hadoop, de código abierto, y la base de datos NoSQL, MongoDB.
La minería de datos, según la Universidad Complutense de Madrid, se define como un campo de la estadística y las ciencias de la computación que permite explorar grandes conjuntos de datos a través de varias técnicas y cuyo objetivo es encontrar patrones y/o anomalías que sirvan para explicar el comportamiento de los datos.
La analítica de datos busca limpiar, transformar y modelar datos para encontrar información útil que ayude a tomar mejores decisiones de negocios, aplicando diferentes técnicas de relacionamiento y agrupamiento de datos.
Por su parte, las tecnologías de visualización de datos son responsables de traducir la información de forma clara a una audiencia, permitiendo incluso contar una historia.
¿Cómo establecer una estrategia de Big Data?
Aunque nadie duda del poder de los datos para la toma de decisiones, Big Data es algo más que buenos deseos. Se necesita una estrategia que permita a las organizaciones establecer prácticas, objetivos y responsabilidades. Aunque existen varias metodologías para diseñar esta estrategia, todas tienen algunos pasos comunes, como los siguientes:
- Definir los objetivos empresariales.
- Realizar una evaluación del estado actual.
- Identificar y priorizar los casos de uso.
- Formular una hoja de ruta.
- Integrar mediante la gestión del cambio.
El potencial de los datos es casi infinito y, por ello, desafiante. Por eso, se debe intentar establecer algunos objetivos claros. ¿Qué pretende cambiar la organización y para cuándo? Este análisis debe incluir conocer los procesos exitosos y comprender qué los hace tan buenos. Para lograr esto, es indispensable involucrar a diferentes elementos de la empresa que trabajan en estos procesos, involucrar el talento y establecer metas realistas.
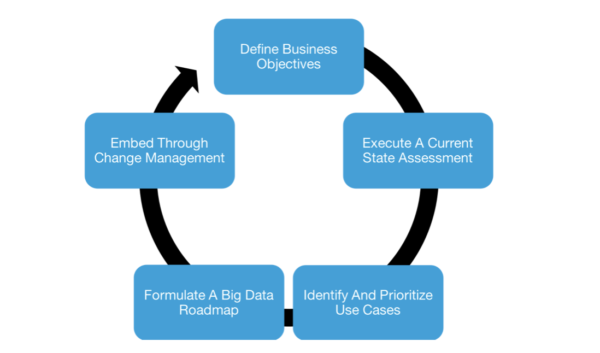
Gráfico: Big Data Framework.
Otra parte fundamental de la estrategia es conocer sobre el terreno en el que estamos pisando. ¿Cómo funcionan los procesos empresariales actuales? ¿Cuáles son las fuentes de datos empleadas? ¿Qué herramientas tecnológicas se usan? ¿Cuáles son las políticas de datos de la organización?
El siguiente paso es identificar y priorizar los casos de uso que tengan mayor potencial de crecimiento y que estén alineados con los objetivos de negocio. Una vez establecidos, se debe pasar al siguiente paso, que es priorizar su implementación según la cantidad de recursos requeridos y su posible impacto en los negocios.
Ninguna estrategia funciona si se queda en el abstracto, es necesario establecer un plan de acción (roadmap) con pasos a seguir, personas responsables, objetivos prioritarios y plazos establecidos.
Por último, algo que va más allá de Big Data y que afecta a toda la organización es incluir la gestión del cambio, apropiarse de ella como un elemento de innovación que ayudará en la implementación de todos los nuevos procesos, incluyendo los de Big Data.
Usos de Big Data por sectores
Big Data es útil para todas las empresas y organizaciones, pero no todas utilizan la información de la misma forma. Por ejemplo, la banca busca el historial crediticio de un cliente antes de aprobarle un crédito, mientras que un médico revisa el historial familiar de un paciente antes de dar un diagnóstico. A continuación, se presentan algunos de los usos más populares de Big Data según el sector del mercado.
Para empezar, el comercio electrónico utiliza Big Data para ofrecer experiencias personalizadas, con recomendaciones a medida que permitan aumentar las ventas y el “engagement” de los clientes. Se trata de un nicho tan grande que se estima que alcanzará los 6.200 millones de dólares para 2025.
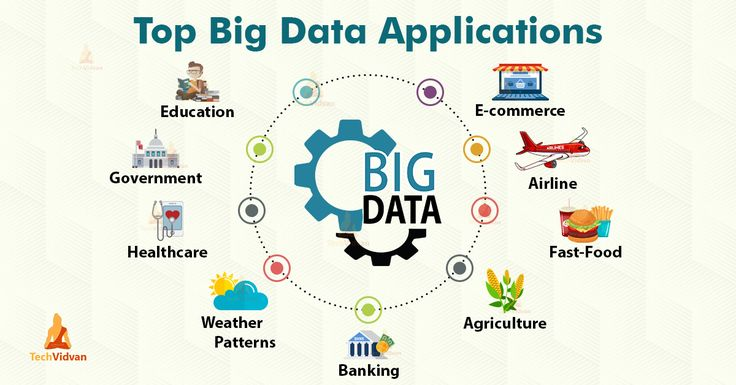
Gráfico: TechVidvam.
En las aerolíneas, Big Data no solo se utiliza para reducir costos y mejorar las ventas, sino que también es fundamental para la seguridad al analizar los datos de los componentes de las aeronaves para saber qué piezas pueden presentar más desgaste y deben ser reemplazadas o revisadas.
En el segmento de comidas rápidas y cadenas de restaurantes, Big Data es tan versátil que se puede utilizar tanto en la planificación de nuevos menús, en función de las tendencias, la época del año, el historial de clientes, etc., como para optimizar el tiempo y la experiencia en los servicios drive-thru.
En la agricultura, Big Data puede ayudar a los agricultores a producir más alimentos y reducir el consumo de agua y pesticidas, e incluso medir la demanda de los productos más solicitados en las grandes ciudades. Esta es una tendencia especialmente importante considerando que, según la ONU, la población alcanzará los 9.700 millones de habitantes en 2050.
Los servicios financieros serían impensables sin el uso de Big Data, ya que se utilizan en numerosos campos que van desde la prevención del fraude financiero hasta la gestión de riesgos y el diseño de nuevos productos.
Los servicios de predicción climática son uno de los grandes usuarios de Big Data, lo que permite generar informes que ayudan a los ciudadanos y empresarios, e incluso generar alertas que permiten salvar vidas al anticiparse a los desastres naturales.
El papel de Big Data en la salud es inmenso, ya que no solo ayuda a los hospitales a ser más eficientes al reducir los tiempos de espera y mejorar las rotaciones de los médicos, sino que también permite generar información para desarrollar mejores medicamentos, crear diagnósticos preventivos, generar alertas y mejorar la experiencia de los pacientes. Por cierto, estamos hablando de una industria que superará los 105.000 millones de dólares para 2030.
Pero no solo el sector privado utiliza Big Data, también los gobiernos lo emplean para mejorar la entrega de servicios a los ciudadanos, crear regulaciones más inteligentes, desarrollar servicios de seguridad más efectivos y mejorar el bienestar y la interacción con los ciudadanos, entre otras posibilidades.
Por último, Big Data también se utiliza ampliamente en el sector educativo, no solo para comparar la oferta y la demanda, sino también para conocer el desempeño de los estudiantes, identificar puntos de falla, entender las motivaciones y desarrollar programas académicos más efectivos.
Big Data e Inteligencia Artificial
Big Data y la Inteligencia Artificial tienen una relación simbiótica. Por un lado, la Inteligencia Artificial necesita enormes cantidades de datos para detectar y generar patrones, crear modelos predictivos, etc. Mientras tanto, Big Data necesita de la Inteligencia Artificial para procesar la inmensa cantidad de datos que se generan diariamente.
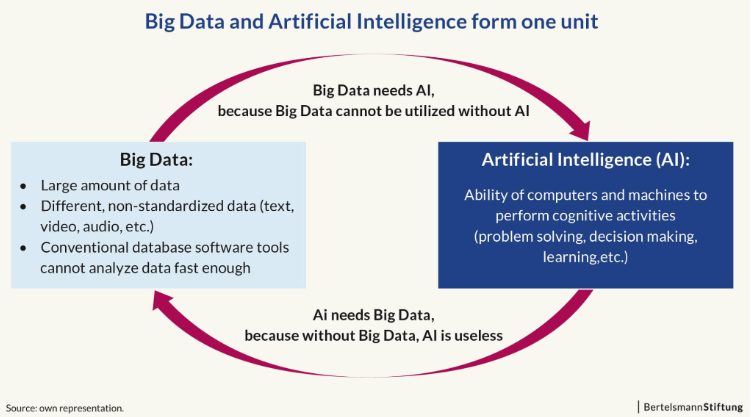
Gráfico: Bertelsmann-stiftung
Pero tal vez una relación más directa se puede apreciar en el aprendizaje automático (Machine Learning), un subcampo de la Inteligencia Artificial que confiere a las computadoras la capacidad de aprender sin ser programadas explícitamente para ello.
Es precisamente Big Data el que proporciona las grandes cantidades de datos de entrenamiento necesarios para un algoritmo de Machine Learning, y es Big Data el que ayuda a mejorar la precisión de estos algoritmos.
Decisiones basadas en datos
Aunque existen varias definiciones, se puede decir que la toma de decisiones basadas en los datos se define como el uso de hechos, métricas y datos para guiar decisiones estratégicas de negocios que se alineen con las metas, los objetivos y las iniciativas de una organización.
En términos empresariales, se habla de empresas basadas en datos (data-driven) para referirse a las organizaciones que han integrado el análisis de datos en el núcleo de sus procesos empresariales y utilizan la información para transformar sus operaciones empresariales.
Gráfico: Replicon
Hablamos de empresas que han reconocido la importancia de los datos y los utilizan para generar una ventaja competitiva. Según cifras de PwC, las organizaciones impulsadas por los datos pueden superar a sus competidores en un 5 % en productividad y un 6 % en rentabilidad.
Gobernanza de datos
Existen varias definiciones. Una sostiene que el gobierno de datos o data governance es una estructura organizativa para apoyar la gestión de datos empresariales. Está formado por un conjunto de normas, políticas y procesos de una organización que garantizan que los datos sean correctos, confiables, seguros y útiles.
Otra definición del Data Governance Institute (DGI) afirma que la Gobernanza de datos es un sistema de derechos de decisión y responsabilidades para los procesos relacionados con la información, ejecutados según modelos que describen quién puede tomar qué acciones con qué información y cuándo.
Existen otras opiniones al respecto, pero básicamente lo que estas definiciones tienen en común es que la Gobernanza de datos crea una estructura y unos responsables para el control de los datos mediante reglas predefinidas.
¿Ahora la pregunta es cuándo es necesario ese gobierno de datos?
Según el Data Governance Institute, las empresas necesitan un gobierno de datos cuando son tan grandes que la gestión tradicional no puede abordar las actividades relacionadas con los datos, cuando las regulaciones del mercado o los gobiernos lo exigen, o cuando las herramientas son tan complejas que obstaculizan otros procesos.
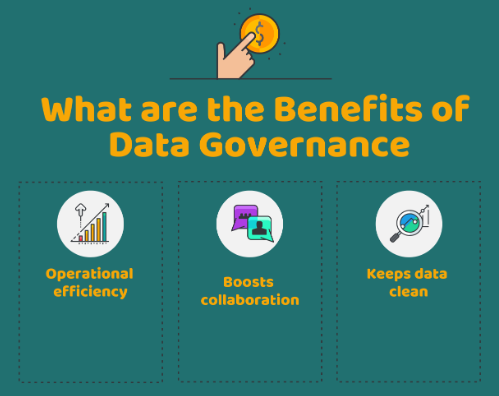
Gráfico: Predictive analytics today
Algunas de las ventajas de este gobierno son una mejor eficiencia operativa, un impulso a los esfuerzos colaborativos y una limpieza de los datos.
En cuanto a la eficiencia, la gobernanza permite que los datos estén en un solo lugar y no pasen de un departamento a otro, evitando la duplicación y las confusiones.
En lo que se refiere a la colaboración, al tener datos abiertos al resto de la organización, se facilita la colaboración y la transparencia de la información.
Por último, la gobernanza se asegura de que se guarden los datos relevantes y no aquellos que se almacenan sin una razón coherente, asegurándose de que la información almacenada sea útil.
Big Data en Colombia
Aunque nadie niega la importancia y las ventajas de Big Data, las estadísticas parecieran contradecirla, al menos en países como Colombia, donde solo 18 % de las empresas sabe aprovechar los datos, según un estudio reciente. Para colmo de males, en este mismo estudio, 71 % de las organizaciones afirmó que los datos impulsan su toma de decisiones.
Estas cifras son respaldadas por otra investigación que mide el Índice de Madurez Analítica (IMA) de las organizaciones y que encontró que Colombia obtiene apenas un puntaje de 46,1 sobre 100, inferior incluso al promedio andino de 49,7 sobre 100.
Este puntaje presenta variaciones al comparar diferentes sectores del mercado, donde los servicios financieros son los líderes locales, con una puntuación de 47,9, seguidos por el sector estatal con 46 puntos. Desafortunadamente, el sector académico es el último del estudio, con apenas 40,3 sobre 100.
El IMA también encontró que apenas 5 % de las organizaciones siempre realiza un análisis predictivo de datos, en contraste con 45 % que casi nunca recurre a los datos para la toma de decisiones, y un 25 % que nunca los utiliza.
Una de las razones expuestas para este puntaje es la falta de talento capacitado, una situación que está cambiando en los últimos años, ya que Big Data, junto con la ciberseguridad, es una de las áreas con mayor crecimiento de talento humano en el país.
Otros retos locales son la falta de metodologías analíticas, que son practicadas por apenas 26 % de las empresas. En cuanto al acceso a la información, 52 % de las empresas cuenta con fuentes de datos (en la nube e internas), pero solo 19 % puede analizarlos cuando se les necesita.
Resumiendo, aunque Colombia ha crecido en sus procesos de Transformación Digital aún le falta en lo referente a sus políticas de datos, una solución que pareciera estar en camino a solucionarse dada la cantidad de talento que se está generando y la generación de políticas locales que buscan promover la conectividad y el ecosistema de emprendedores. Sin embargo, aún falta bastante trabajo en este campo.
Imagen principal: Freepik.





